"If I take one more step, it'll be the farthest away from home I've ever been."
I am working on some kind of a japanese RPG game engine clone. The original engine is a Windows application. My goal, at the moment, is to provide a level editor UI to enable one to edit game source files as would the original editor do BUT with a modern look and feel and user experience.
To do that, I decided to start learning C++ (Yeah, this is my first C++ toy project!), modern OpenGL 1, a bit of GLFW, and immediate mode GUI programming thanks to Dear ImGui.
Once I managed to put all of these together, I went on to work on a part of the editor that is used to edit the magics available for the game. And, girlz'n'boyz, I wouldn't have guessed that what could go SO WRONG and be a journey on itself. Why? Glad you asked. Buckle up.
"Po-tay-toes!"
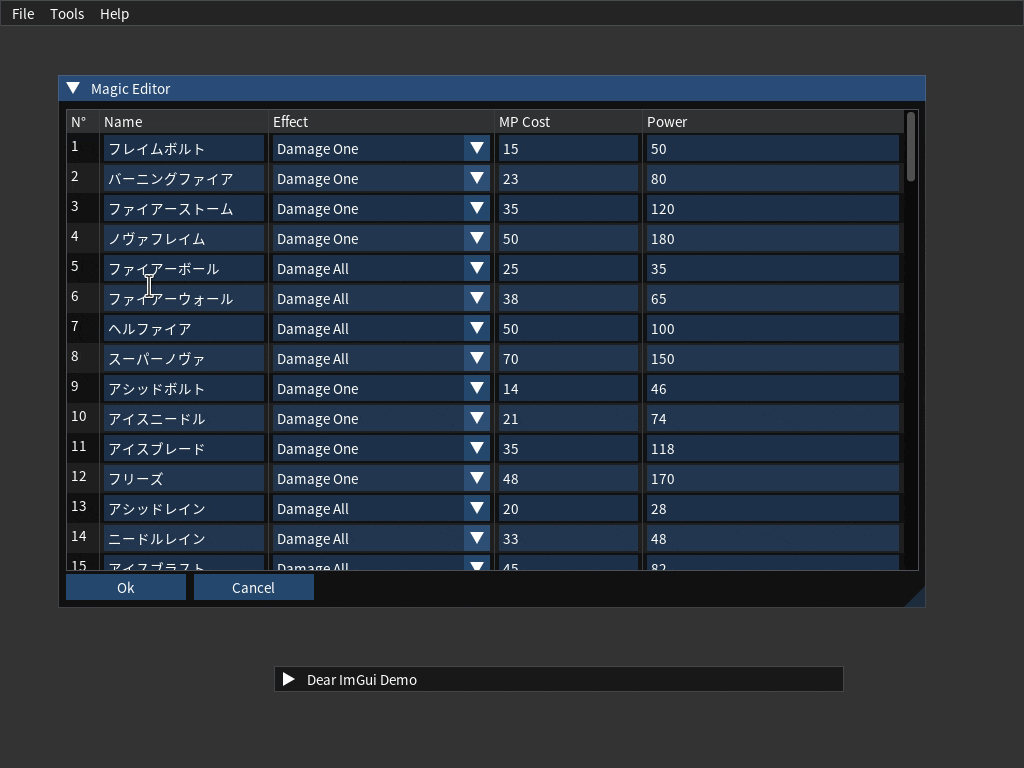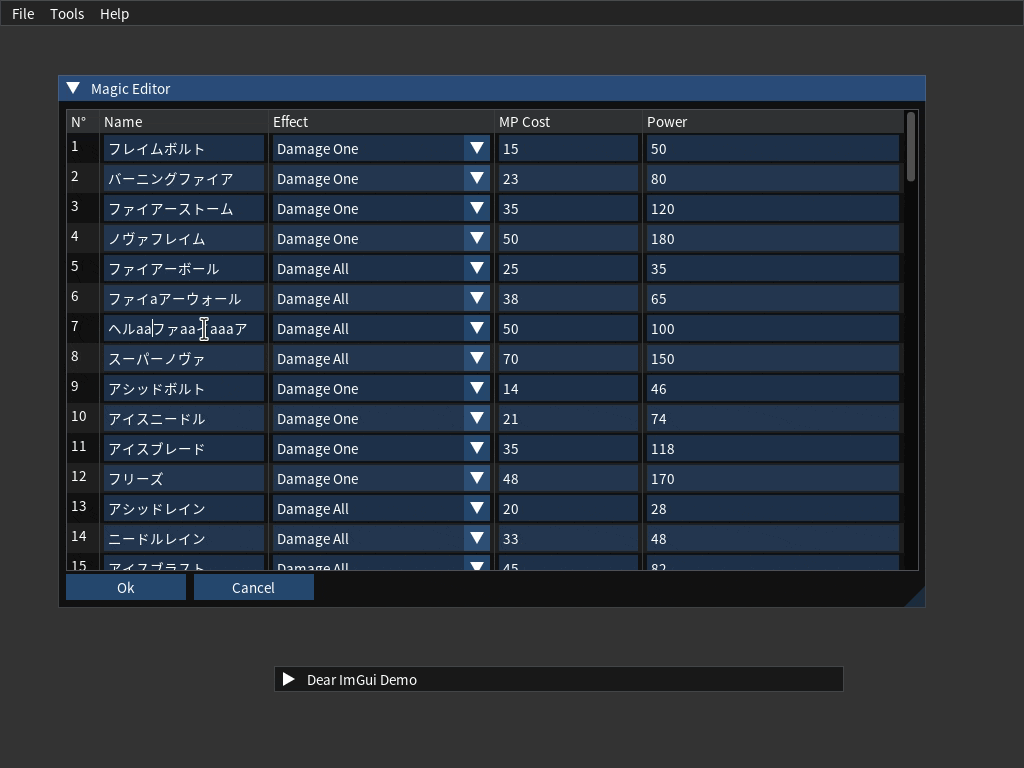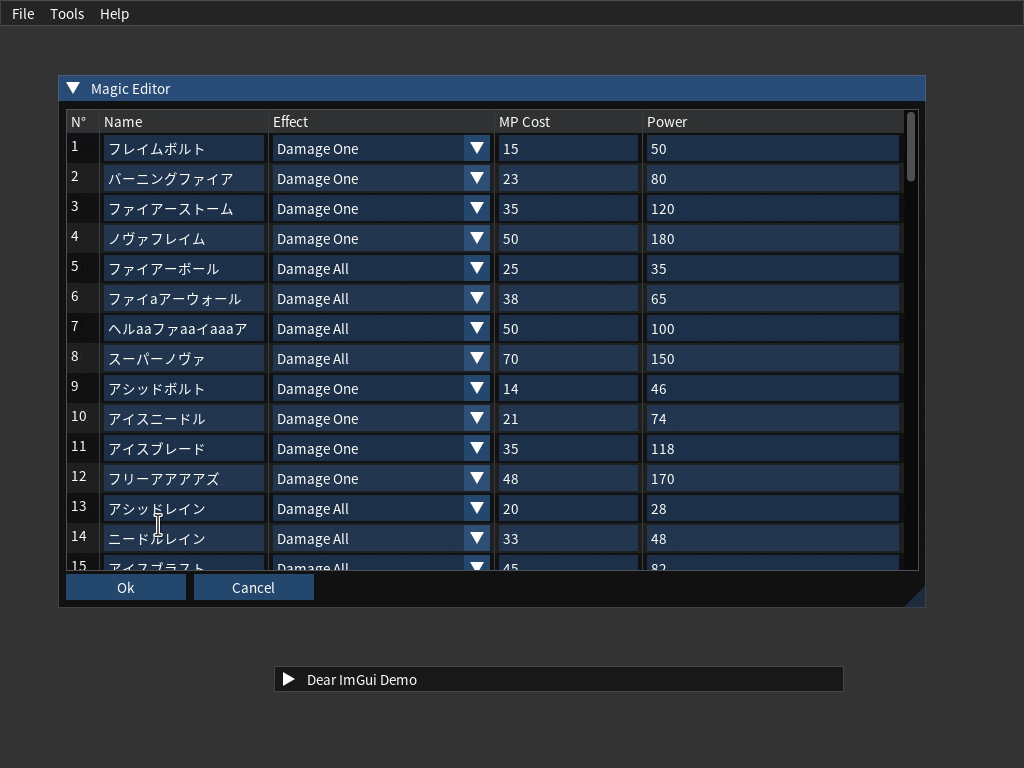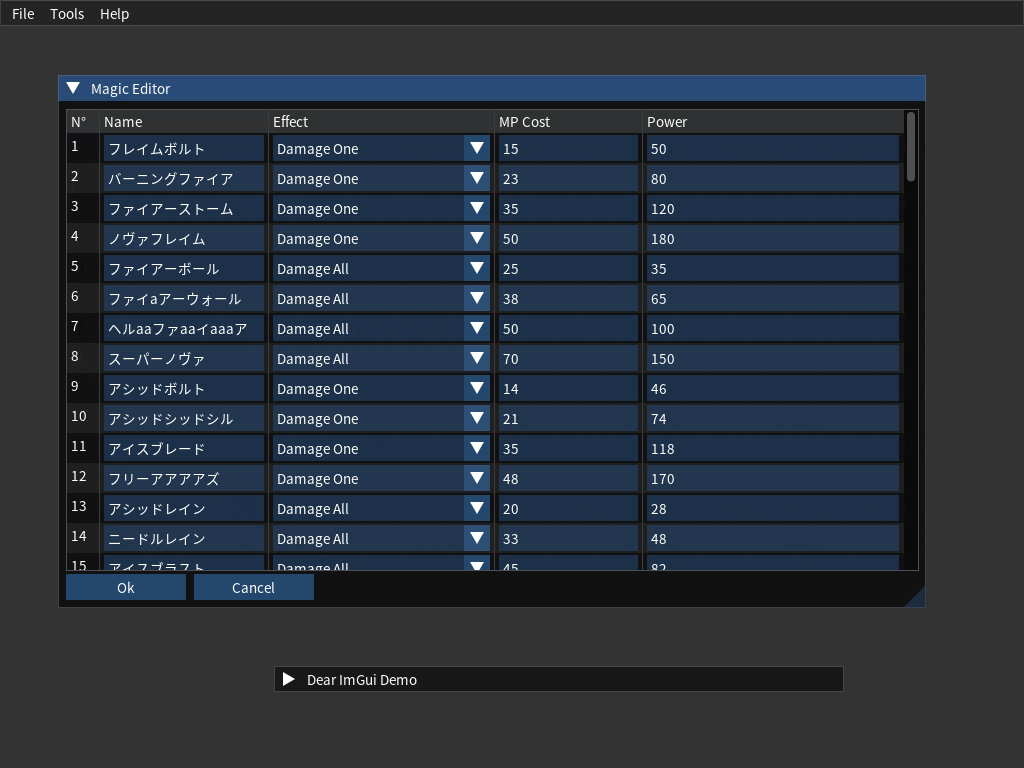
A magic is a simple game object. It has a kind of magic, a cost to cast, a power level and a name. Nice, pretty and simple, right?
Magics are stored in a single binary data file:
- Without magic number.
- 100 magic game objects' stored one after the other:
- An 32-bits unsigned integer to store the magic kind.
- An 16-bits unsigned integer to store the cost to cast the magic.
- Another 16-bits unsigned integer to store the power of the magic.
- 20 bytes to store the name of the magic.
- aaaaand... ah well nothing. It is really a simple layout.
Okay, so on the ImGui side we just go:
void MagicEditor::ui() {
if (window_opened) {
ImGui::Begin("Magic Editor", &window_opened);
static ImGuiTableFlags flags = ImGuiTableFlags_ScrollY | ImGuiTableFlags_RowBg | ImGuiTableFlags_BordersOuter | ImGuiTableFlags_BordersV | ImGuiTableFlags_Resizable;
ImVec2 window_size = ImGui::GetWindowSize();
ImVec2 outer_size = ImVec2(0.0f, window_size.y - (ImGui::GetFontSize() + ImGui::GetFrameHeight()*2));
if (ImGui::BeginTable("table_scrolly", 5, flags, outer_size))
{
ImGui::TableSetupScrollFreeze(0, 1);
ImGui::TableSetupColumn("N°", ImGuiTableColumnFlags_WidthFixed | ImGuiTableColumnFlags_NoResize);
ImGui::TableSetupColumn("Name");
ImGui::TableSetupColumn("Effect");
ImGui::TableSetupColumn("MP Cost");
ImGui::TableSetupColumn("Power");
ImGui::TableHeadersRow();
for (int row = 0; row < MAGIC_COUNT; row++)
{
ImGui::PushID(row);
ImGui::TableNextRow();
ImGui::TableNextColumn();
ImGui::Text("%d", row + 1);
ImGui::TableNextColumn();
ImGui::SetNextItemWidth(-FLT_MIN);
std::string name = magics[row].name;
if (ImGui::InputText("##name", &name)){
magics[row].name = name;
}
ImGui::TableNextColumn();
ImGui::SetNextItemWidth(-FLT_MIN);
if (ImGui::BeginCombo("##type", MagicTypeString[magics[row].type])) {
for (auto i = 0; i < IM_ARRAYSIZE(MagicTypeString); i++) {
const bool is_selected = (magics[row].type == i);
if (ImGui::Selectable(MagicTypeString[i], is_selected)) {
magics[row].type = MagicType(i);
}
if (is_selected) {
ImGui::SetItemDefaultFocus();
}
}
ImGui::EndCombo();
}
ImGui::TableNextColumn();
ImGui::SetNextItemWidth(-FLT_MIN);
int cost = magics[row].cost;
if (ImGui::InputInt("##cost",&cost,0)) {
magics[row].cost = cost;
}
ImGui::TableNextColumn();
int power = magics[row].power;
ImGui::SetNextItemWidth(-FLT_MIN);
if (ImGui::InputInt("##power", &power,0)) {
magics[row].power = power;
}
ImGui::PopID();
}
ImGui::EndTable();
}
if (ImGui::Button("Ok", ImVec2(120, 0))) {
save();
window_opened = false;
}
ImGui::SameLine();
if (ImGui::Button("Cancel", ImVec2(120, 0))) {
reset();
window_opened = false;
}
ImGui::End();
}
}
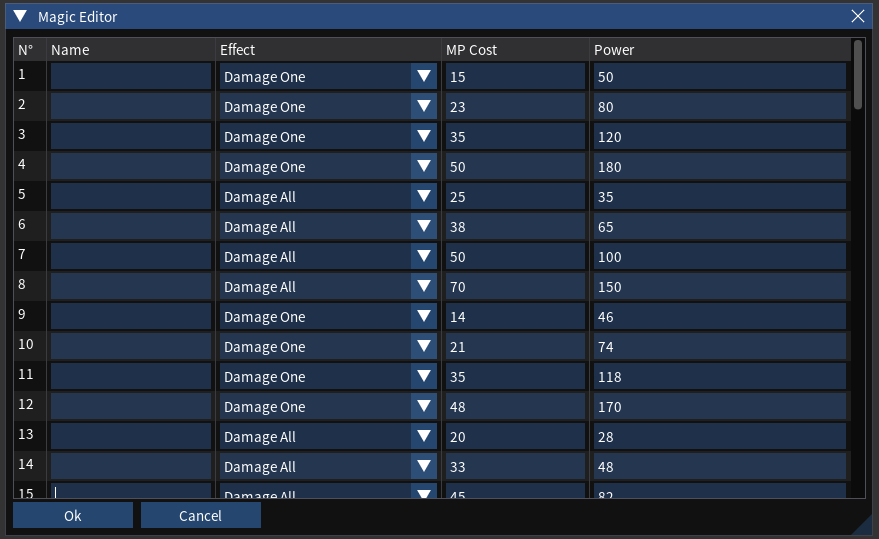
Well that was easy!
Now we want to load and store the magic name so that it won't break the original game engine. This should be easy too. Right? ... Right?
Remember when I said that it was a japanese game engine? How would you load japanese text from a binary file?
"Text encodings. The one place in computer-earth we don't want to see any closer, and the one place we're trying to get to."
Please, please note that I did not do a lot of research and that the following section may be full of errors. I invite you to seek information for each subject you deem interesting.
Text encoding is easy
Since the beginning of computing age, mankind stored text as bits next to each other. Bits made bytes. And many bytes organized in specific ways meant text.
At first, in 1969, it was simple:
Let's create a way to store english text and create a communication code (or text encoding) to exchange data in a standard way. And make it clear that it is American please. 256 bits in a byte? We don't need more than 128 bits ahah. LETSGO!
And there was born the ASCII.
Text encoding is not so simple...
Duh. What an ethnocentric point of view. Most communities went one to derive from ASCII and create their own code page: a way to organize one or more bytes to represent characters that would not fit into the 256 possibilities of a byte.
JIS X
Also on 1969, the Japanese Industrial Standards (JIS) X section dedicated to information processing created the JIS X 0201: 96 bits to represent compatibility with ISO646 (and therefore ASCII) and 96 other bits to represent only phonetic katakana signs. This was enough for simplified written japanese, but it could not represent the hiragana and kanji signs.
JIS X 0208 was created in 1978 and enabled 6879 characters to be represented through a two-bytes encoding: Numerals, Latin letters, Hiragana, Katakana, Greek Letters, Cyrillic letters, Box-drawing characters and Kanji. Phew.
Shift-JIS
In the 1980, both encoding where widely in use on japanese computers. As small japanese company2 and Microsoft worked together to bind them in a single encoding in order to establish a new japanese standard : Shift JIS / SJIS.
It cleaverly use unassigned code points in JIS X 0201 to be the lead bytes of JIS X 0208 code points (Lead bytes are "shifted" around the initial 64 half-width katakana characters).
Shift JIS is backward compatible with JIS X 0201. Windows code page 932 is a Microsoft extension to Shift JIS.
Text encoding is hard!
And what if humanity needed a unique code to communicate. A unique... code...
In 1991, a consortium created the first version of the Unicode Standard. It is designed to support the use of text written in all the world's major writing systems.
3 encodings
The standard defines three encodings: UTF-8, UTF-16 and UTF-32.
Each one define the numbers of bits required to encode code points of a text.
I won't go into explaining when you should use one or the other. It depends. Please go ahead and start reading if you want to, but this post is not an in-depth explanation of the Unicode Transformation Formats.
UTF-8: The best hack
- It is backward with ASCII.
- It can encode all 1112064 Unicode code points with one to four bytes.
- It is available from C++11 with the u8 prefix.
- It as been implemented in all modern operating systems.
- It encodes 98.2% of all web pages (at least in 2024).
- It was baked by Ken Thompson and Rob Pike.
- It is both simple AND complex.
- It is beautiful.
- It is the best hack.
"Do you remember the taste of strawberries?"
Back to our matter: how to load/write japanese text from/to a binary file? What we know:
- We live in a world where UTF-8 is everywhere.
- We'll need to convert Shift JIS strings to UTF-8. UTF-8 is a "superset" of Shift JIS.
- We'll need to convert UTF-8 strings to Shift JIS. Only a subset of UTF-8 characters can be translated to Shift JIS.
- Our binary file to store magics allow only for 20 Shift JIS bytes per magic for it's name.
- Dear ImGui allow for UTF-8 text input an display.
- We are using C++.
- Encodings are fracking hard.
Let's first start by handling strings encoding conversion.
"It's me! It's your encoding! Don't you know your encoding?"
Here is an helper function to translate strings using iconv.
Let's review quickly this function inputs:
inis the input bufferin_encodingis the source text encoding, we will useUTF-8orShift_JISoutis the output bufferout_encodingis the destination text encodingout_lenis the output buffer length, theoutbuffered will be cleared before conversionignore_invalidif we should fail when an invalid multibyte sequence is encountered during the conversion
#include <cerrno>
#include <cstdio>
#include <cstring>
#include <iconv.h>
bool convert(char *in, const char *in_encoding, char *out, const char *out_encoding, int out_max_len, bool ignore_invalid) {
// Clear destination buffer
memset(out, 0, out_max_len);
size_t in_len = strlen(in);
size_t out_len = out_max_len - 1;
size_t iconv_result = 0;
bool failed = false;
// Allocate descriptor for character set conversion
iconv_t conv = iconv_open(out_encoding, in_encoding);
if (conv == (iconv_t)-1) {
std::perror("iconv_open failed");
return false;
}
// Perform character set conversion
do {
iconv_result = iconv(conv, &in, &in_len, &out, &out_len);
if (iconv_result == (size_t)-1) {
// Conversion failed
switch (errno) {
case EILSEQ: {
// An invalid multibyte sequence was encountered in the input
if (!ignore_invalid) {
failed = true;
break;
}
} break;
default:
failed = true;
break;
}
}
} while (iconv_result != 0 && !failed);
if (iconv_result == (size_t)-1) {
std::perror("iconv failed");
}
// Deallocate descriptor for character set conversion
if (iconv_close(conv) == -1) {
std::perror("iconv_close failed");
failed = true;
}
return failed;
}
The function is pretty straightforward:
- We first clear the output buffer to ensure a null-terminated output character string.
- We then use
iconv_opento get the conversion descriptor for the given encodings. - We perform the conversion through
iconv. - We release the conversion descriptor with
iconv_close. - We return a boolean to tell if conversion was okay or not.
Here is an usage example to convert an UTF-8 string to a Shift JIS one:
// An UTF-8 input string
char input[] = u8"さくら";
int input_len = std::strlen(input)+1;
// A Shift JIS buffer
char *pSJIS = reinterpret_cast<char *>(std::malloc(input_len));
std::memset(pSJIS, 0, input_len);
// Perform the conversion
bool failed = convert(input, "UTF-8", pSJIS, "Shift_JIS", input_len);
UTF-8 and Shift JIS encodings ensure that strings are null-terminated and that no null byte will be encountered before the end of the text.
A Shift JIS translated string should always be of equal or shorter length than an UTF-8 string, so it is okay to create it with the same length as the source string.
How do we know what length to use to convert from Shift JIS to UTF-8? Well: we don't. Or at least
I didn't not try to find how to. So I used this other helper function, assuming that I won't need
Shift JIS strings with an UTF-8 transliterated length over ICONV_BUFFER_SIZE:
#define ICONV_BUFFER_SIZE 1024
std::string convert(char *in, const char *in_encoding, const char *out_encoding, bool ignore_invalid) {
char buffer[ICONV_BUFFER_SIZE] {};
char *out = buffer;
size_t out_len = sizeof(buffer);
if (convert(in, in_encoding, out, out_encoding, out_len, ignore_invalid)) {
return "";
}
return buffer;
}
Okey-dokey! We now can read magic names from our binary file to display them in our UI. Noice.
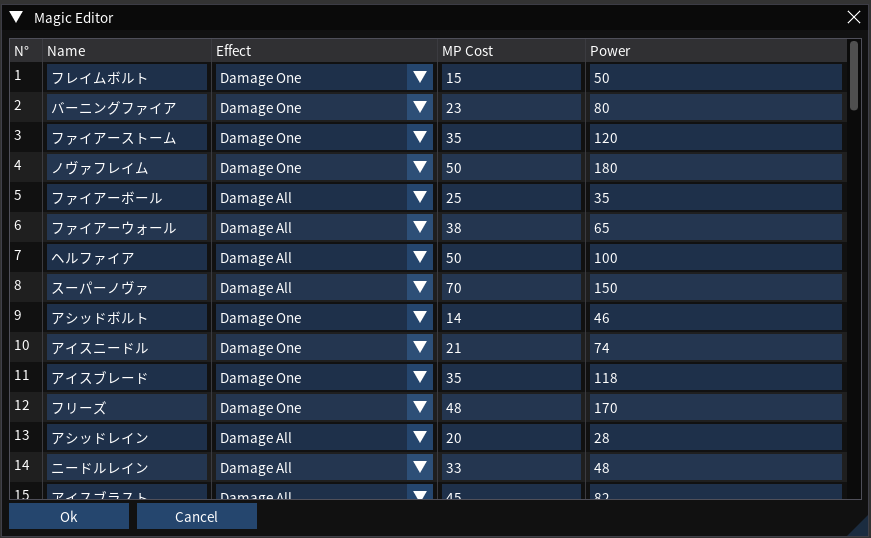
"There's some input in this text box, dear ImGui, And it's worth filtering for."
Now that we can display our magic names in the editor, we need to provide a way to edit them.
BUT, we want to :
- filter out non-translatable to Shift JIS characters and
- restrict their length so that it won't be over the 20 Shift JIS bytes allowed in the game binary file!
To explain these concepts, lets put our magic on the back burner and take a simple example:
- The current text is the UTF-8 string
さくらですか。These are 7 3-bytes Unicodecode points. - The text box edit cursor is at position 9 (between the
らand theでcharacters).
sa ku ra | de su ka ?
e3,81,95,e3,81,8f,e3,82,89,|,e3,81,a7,e3,81,99,e3,81,8b,e3,80,82,00
- The user wants to paste the UTF-8 string
は🌸cherry blossom🌸/はな. - But we only have 23 Shift JIS bytes available for output storage.
This result in the UTF-8 string さくらは🌸cherry blossom🌸/はなですか。, moving the cursor to position 41:
sa ku ra ha 🌸 c h e r r y _ b l o s s o m 🌸 / ha na | de su ka ?
e3,81,95,e3,81,8f,e3,82,89,e3,81,af,f0,9f,8c,b8,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,f0,9f,8c,b8,2f,e3,81,af,e3,81,aa,|,e3,81,a7,e3,81,99,e3,81,8b,e3,80,82,00
Believe me, this won't fit in 23 bytes, even in Shift JIS. Plus it has some emojis that do not exist in the Shift JIS world!
ImGui text filtering capabilities
Hopefully, ImGui provide text filtering capabilities that are the perfect tool to achieve our goals.
First we need to include ImGui C++ string handling header:
#include "misc/cpp/imgui_stdlib.h"
This header provide the following function:
IMGUI_API bool InputText(const char* label, std::string* str, ImGuiInputTextFlags flags = 0, ImGuiInputTextCallback callback = nullptr, void* user_data = nullptr);
labelis the label to display next to the inputstris the string we want to editflagsare theImGuiInputTextFlagsflags to control when we want the callback to be calledcallbackis anImGuiInputTextCallback: an input text callback to filter the input through anImGuiInputTextCallbackDatapayload.user_datais additionnal data that can be used while filtering the input
So we can use it like this: we will setup a sjis_text_filter callback, and pass the maximum
magic name length allowed.
int max_magic_name_len {MAGIC_NAME_LEN - 1};
std::string name = magics[row].name;
if (ImGui::InputText("Magic Name", &name, ImGuiInputTextFlags_CallbackEdit, sjis_text_filter, &max_magic_name_len)) {
magics[row].name = name;
}
Here is our bare-bones sjis_text_filter function's skeleton:
int sjis_text_filter(ImGuiInputTextCallbackData *data) {
// ...
// Here we should filter the input.
//
// data provides the following elements:
// char* Buf; // Text buffer // Read-write
// int BufTextLen; // Text length (in bytes) // Read-write
// bool BufDirty; // Set if you modify Buf/BufTextLen! // Write
// int CursorPos; // // Read-write
// ...
return 0;
}
Stripping non convertible UTF-8 characters
Okay, we can start by trying to convert the UTF-8 string to Shift JIS:
// Find out input string total length
int input_len = std::strlen(data->Buf)+1;
// Create a Shift JIS work buffer
char *pSJIS = reinterpret_cast<char *>(std::malloc(input_len));
std::memset(pSJIS, 0, input_len);
convert(data->Buf, "UTF-8", pSJIS, "Shift_JIS", input_len);
This will fail:
iconv failed: Invalid or incomplete multibyte or wide character
Meh, this is because 🌸 can't be translated to Shift JIS.
iconv enable us to transliterate: write words in another alphabet.
We can use this capability by specifying //TRANSLIT after the destination encoding string. We also need to specify that we don't want to fail when we encounter an invalid or incomplete multibyte or wide character. Try again:
convert(data->Buf, "UTF-8", pSJIS, "Shift_JIS//TRANSLIT", input_len, true);
Conversion is then successful! The pSJIS buffer looks like this:
sa ku ra ha ? c h e r r y _ b l o s s o m ? / ha na de su ka ?
82,b3,82,ad,82,e7,82,cd,3f,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,3f,2f,82,cd,82,c8,82,c5,82,b7,82,a9,81,42,00
This is a correct Shift JIS text buffer with two bytes per character!
But something is off: If we were to display the Shift JIS string, it would be: さくらは?cherry blossom?/はなですか。. The emojis were replaced by question marks ?. This is what happen when characters that are outside of the target character set that can't be transliterated are processed.
When this can defintely be of some use, we really just want to strip them. We can use //IGNORE to do that:
convert(data->Buf, "UTF-8", pSJIS, "Shift_JIS//IGNORE", input_len, true);
Now we have the following Shift JIS string: さくらはcherry blossom/はなですか。
sa ku ra ha c h e r r y _ b l o s s o m / ha na de su ka ?
82,b3,82,ad,82,e7,82,cd,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,2f,82,cd,82,c8,82,c5,82,b7,82,a9,81,42,00
We successfully removed untransliterable characters from the input string to the output format. Convert it back to UTF-8.
convert(pSJIS, "Shift_JIS", data->Buf, "UTF-8", input_len);
If we were to print the UTF-8 with the current cursor position, we would get the following issue:
sa ku ra ha c h e r r y _ b l o s s o m / ha na de su ka ?
e3,81,95,e3,81,8f,e3,82,89,e3,81,af,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,2f,e3,81,af,e3,81,aa,e3,81,a7,e3,81,99,e3,81,|,8b,e3,80,82,00
Note how the cursor is in the middle of a multibyte UTF-8 character? We need to update it to reflect the removed characters. Finally, we update the buffer len and set the input buffer as dirty to announce at ImGui that we updated it. Obviously, we don't forget to free the Shift JIS buffer.
data->CursorPos -= (input_len - 1 - std::strlen(data->Buf));
data->BufTextLen = std::strlen(data->Buf);
data->BufDirty = true;
std::free(pSJIS);
Now we have the following UTF-8 input string and cursor position:
さくらはcherry blossom/はな|ですか。
sa ku ra ha c h e r r y _ b l o s s o m / ha na de su ka ?
e3,81,95,e3,81,8f,e3,82,89,e3,81,af,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,2f,e3,81,af,e3,81,aa,|,e3,81,a7,e3,81,99,e3,81,8b,e3,80,82,00
It works! However, we saw that the Shift JIS is well over our required output length.
Here is the complete filter function code at this point:
int sjis_text_filter(ImGuiInputTextCallbackData *data) {
int input_len = std::strlen(data->Buf)+1;
// Create a Shift JIS work buffer
char *pSJIS = reinterpret_cast<char *>(std::malloc(input_len));
std::memset(pSJIS, 0, input_len);
// Transliterate to Shift JIS, ignoring everything that can't be converted
convert(data->Buf, "UTF-8", pSJIS, "Shift_JIS//IGNORE", input_len, true);
// Transliterate back to UTF-8
convert(pSJIS, "Shift_JIS", data->Buf, "UTF-8", input_len);
// Update ImGui buffer length, set it dirty and update edit cursor position
data->CursorPos -= (input_len - 1 - std::strlen(data->Buf));
data->BufTextLen = std::strlen(data->Buf);
data->BufDirty = true;
// Do not forget to free the work buffer
std::free(pSJIS);
return 0;
}
Sizing input to match required output length
We suppose that our original UTF-8 text complies to our Shift JIS output length rule. The user pasted another chunk of UTF-8 input that was added at the previous cursor location. We just removed any character that could not be transliterated to Shift JIS and updated accordingly the cursor position to reflect that removal.
Now we can face two cases:
- Either the matching Shift JIS output string is still under our output length rule.
- In that case, everything is fine! We do not have any more work to do.
- Or it is outside of the requested bound mandated by the rule.
- In this case, we need to remove any UTF-8 code point from the chunk that make the output string break the rule until it don't break it anymore. This could be one, or all of the input chunk's codepoints. If any code point was to be removed, we need to update the ImGui cursor position to reflect the final edit position.
Yeah. Right. But... what is an UTF-8 code point anyway? And how to remove it from a buffer without making the UTF-8 text invalid?
I can only count to four
As stated previously, UTF-8 is the most beautiful hack.
You can look at any byte in an UTF-8 string and find out if you are on a boundary (between two code points) or in the middle of a code point just by checking the byte content!
There are only 4 situations:
- Either you are at the end of the string, the byte is therefore the null terminator byte:
0x00. - Either you are on a single byte code point: code point from
0x01to0x7F. - Either you are on a control byte, indicating how many bytes are following the given byte. This
can be checked with the 4 highest bits of the byte.
110X XXXXmeans that this control byte is followed by 1 continuation byte1110 XXXXmeans that this control byte is followed by 2 continuation bytes1111 XXXXmeans that this control byte is followed by 3 continuation bytes
- Either you are on a continuation byte, in that case, the 2 highest bits of the byte should be
10XX XXXX.
This means that you can find where you are in the text buffer in an efficient way. Beautiful.
Lets find the size of a codepoint at any place in a buffer, shall we?
int get_code_point_size(char *str, int str_len, int pos) {
if ((pos < 0) || (pos > str_len)) {
return -1;
}
switch(str[pos] & 0xf0) {
case 0xc0 : {
if (((pos + 1) <= str_len) &&
((str[pos+1] & 0xc0) == 0x80)) {
return 2;
}
} break;
case 0xe0 : {
if (((pos + 2) <= str_len) &&
((str[pos+1] & 0xc0) == 0x80) &&
((str[pos+2] & 0xc0) == 0x80)) {
return 3;
}
} break;
case 0xf0 : {
if (((pos + 3) <= str_len) &&
((str[pos+1] & 0xc0) == 0x80) &&
((str[pos+2] & 0xc0) == 0x80) &&
((str[pos+3] & 0xc0) == 0x80)) {
return 4;
}
} break;
default : {
if ((str[pos] & 0xff) < 0x7f) {
return 1;
}
}
};
return -1;
}
This function returns:
-1if we are outside the buffer, on the null terminator or on an invalid UTF-8 byte.1,2,3,4on correct UTF-8 code point thanks to the control bytes.
Where does start this UTF-8 code point?
Now that we can find a code point boundary and it's size, we can find the code point position in the buffer:
int get_code_point_start(char *str, int str_len, int pos) {
if ((pos < 0) || (pos > str_len)) {
return -1;
}
int limit = pos - 3;
while (pos >= 0 && pos >= limit) {
if (get_code_point_size(str, str_len, pos) != -1) {
return pos;
}
pos--;
}
return -1;
}
This function returns:
-1if we checked for a code point byte outside the buffer, or if we could not find a valid code point boundary by backtracking until the start of the buffer or at most 3 bytes before the given position or ...- The start position of the code point.
Use the flamethrower!
Thanks to the two previous functions, we can erase an UTF-8 codepoint in a buffer:
int erase_code_point_at(char *input, int pos) {
int input_len = std::strlen(input);
int code_point_start = get_code_point_start(input, input_len, pos);
if (code_point_start == -1) {
return -1;
}
int code_point_size = get_code_point_size(input, input_len, code_point_start);
int code_point_end = code_point_start + code_point_size;
std::memmove(input + code_point_start,
input + code_point_end,
strlen(input + code_point_end) + 1);
return code_point_start;
}
This function returns:
-1if no valid code point was found at the given position or...- The start position of the code point.
"Let him go, you filth!"
Alright, we have all we need to fix our input!
int sjis_text_filter(ImGuiInputTextCallbackData *data) {
int input_len = std::strlen(data->Buf)+1;
// Create a Shift JIS work buffer
char *pSJIS = reinterpret_cast<char *>(std::malloc(input_len));
std::memset(pSJIS, 0, input_len);
// Transliterate to Shift JIS, ignoring everything that can't be converted
convert(data->Buf, "UTF-8", pSJIS, "Shift_JIS//IGNORE", input_len, true);
// Transliterate back to UTF-8
convert(pSJIS, "Shift_JIS", data->Buf, "UTF-8", input_len);
// Update edit cursor position
data->CursorPos -= (input_len - 1 - std::strlen(data->Buf));
// Trim until we match our output length rule
while (std::strlen(pSJIS) > (size_t)(*(int*)(data->UserData))) {
// Erase previous UTF-8 code point and move cursor accordingly
data->CursorPos = erase_code_point_at(data->Buf, data->CursorPos - 1);
// Update Shift JIS work buffer
convert(data->Buf, "UTF-8", pSJIS, "Shift_JIS", input_len);
}
// Update ImGui buffer length, set it dirty
data->BufTextLen = std::strlen(data->Buf);
data->BufDirty = true;
// Do not forget to free the work buffer
std::free(pSJIS);
return 0;
}
Is everything fine?
Remember our test case:
- The current text is the UTF-8 string
さくらですか。 - The text box edit cursor is at position 9 (between the
らand theでcharacters). - The user wants to paste the UTF-8 string
は🌸cherry blossom🌸/はな. - This result in the UTF-8 string
さくらは🌸cherry blossom🌸/はなですか。, moving the cursor to position 41:
sa ku ra ha 🌸 c h e r r y _ b l o s s o m 🌸 / ha na | de su ka ?
e3,81,95,e3,81,8f,e3,82,89,e3,81,af,f0,9f,8c,b8,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,f0,9f,8c,b8,2f,e3,81,af,e3,81,aa,|,e3,81,a7,e3,81,99,e3,81,8b,e3,80,82,00
The first step of the filter remove characters that can't be translated to Shift JIS and update the cursor position accordingly:
sa ku ra ha c h e r r y _ b l o s s o m / ha na de su ka ?
e3,81,95,e3,81,8f,e3,82,89,e3,81,af,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,2f,e3,81,af,e3,81,aa,|,e3,81,a7,e3,81,99,e3,81,8b,e3,80,82,00
Now we check the Shift JIS content and length at each step:
Shift JIS (35): 82,b3,82,ad,82,e7,82,cd,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,2f,82,cd,82,c8,82,c5,82,b7,82,a9,81,42,00
UTF8: e3,81,95,e3,81,8f,e3,82,89,e3,81,af,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,2f,e3,81,af,|,e3,81,a7,e3,81,99,e3,81,8b,e3,80,82,00
Shift JIS (33): 82,b3,82,ad,82,e7,82,cd,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,2f,82,cd,82,c5,82,b7,82,a9,81,42,00
UTF8: e3,81,95,e3,81,8f,e3,82,89,e3,81,af,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,2f,|,e3,81,a7,e3,81,99,e3,81,8b,e3,80,82,00
Shift JIS (31): 82,b3,82,ad,82,e7,82,cd,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,2f,82,c5,82,b7,82,a9,81,42,00
UTF8: e3,81,95,e3,81,8f,e3,82,89,e3,81,af,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,|,e3,81,a7,e3,81,99,e3,81,8b,e3,80,82,00
Shift JIS (30): 82,b3,82,ad,82,e7,82,cd,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,6d,82,c5,82,b7,82,a9,81,42,00
UTF8: e3,81,95,e3,81,8f,e3,82,89,e3,81,af,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,|,e3,81,a7,e3,81,99,e3,81,8b,e3,80,82,00
Shift JIS (29): 82,b3,82,ad,82,e7,82,cd,63,68,65,72,72,79,20,62,6c,6f,73,73,6f,82,c5,82,b7,82,a9,81,42,00
UTF8: e3,81,95,e3,81,8f,e3,82,89,e3,81,af,63,68,65,72,72,79,20,62,6c,6f,73,73,|,e3,81,a7,e3,81,99,e3,81,8b,e3,80,82,00
...
Shift JIS (22): 82,b3,82,ad,82,e7,82,cd,63,68,65,72,72,79,82,c5,82,b7,82,a9,81,42,00
UTF-8: e3,81,95,e3,81,8f,e3,82,89,e3,81,af,63,68,65,72,72,79,|,e3,81,a7,e3,81,99,e3,81,8b,e3,80,82,00
sa ku ra ha c h e r r y | de su ka ?
The result is さくらはcherryですか。, with cursor at position 18!
"Well, I'm back."
Phew.
This maybe an easy one to read, but it was not so obvious to me. I hope that this was a nice introduction to text filtering of UTF-8 / Shift JIS with Dear ImGui to you, and that my game engine clone will be out one day.
What if it is not?
Well, I learned many things along the way. And this is why I do these toy projects.
Oof, tough one. I kept Vulkan for later he...
Funny thing, ASCII Corporation is also the company that made the game engine I'm trying to be compatible with. Could you guess which one? 😅